How Large-Scale Data Migrations Actually Work

Data migration is a key step for breaking down data silos — a major undertaking many organizations have planned for 2026. Yet, for all its strategic weight, large-scale data migrations are often treated as tomorrow’s problem and get deprioritized in favor of other initiatives.
The hesitation is understandable. Production data migration introduces major risks: service disruption, data integrity issues, compliance exposure, and unforeseen downstream impact on customers, reporting, and operations.
A recent survey found that only 6% of challenging database migration projects were completed on the original schedule, mostly because the condition of the source data and the complexity of existing dependencies were discovered too late in the process.
This often reinforces the perception that these initiatives are high effort with uncertain payoff, which isn’t the case, as we’ll explain in this post, together with Yurii Halych from our Data Engineering team. Yurii shared some of the practices we use to ensure that your data migration project doesn’t cause operational slowdowns and customer experience issues.
Table of Contents
How Does Data Migration Work
At a limited scale, data migration focuses on record transfer between systems. But this approach is only workable when schemas are stable, validation rules are consistently enforced, and downstream consumers can tolerate limited variability, which isn’t always the case.
Most companies consistently face increasing data volume and system complexities, which broaden the migration scope. Production datasets change as platforms evolve, integrations are added, and business definitions shift across teams.
So if you’re building a data migration strategy for MySQL, Elasticsearch, or OpenSearch, Logstash pipelines, or custom ETL workflows, the process should involve four phases:
- Data profiling
- Data transformation
- Ingestion control
- Validation
Understand the Source Data
Data migration risks concentrate in the source systems. Databases that have been running for years usually carry some history with them, including multiple representations of the same business concept created through integrations, reprocessing, and manual fixes.
Typical issues we see in many databases include:
- Mixed formats within a single field, such as numeric identifiers stored alongside placeholders like “NULL” or “N/A”.
- Nested structures flattened into text blobs to work around earlier schema constraints.
- Address fields that inconsistently combine street names, units, and directional information across records.
- Deprecated fields that remain populated long after their original business meaning has changed.
Carrying these patterns forward to a new system increases TCO and promotes further data silos. Also, downstream analytics tools compensate for poor data quality through additional transformation logic, which raises maintenance effort and reduces confidence in outputs.
To deal with these issues, we recommend starting with Source data profiling. It reduces migration risk by establishing a clear baseline before design decisions are locked in. Plus, it exposes inconsistencies that would otherwise surface later as ingestion failures or reporting errors.
We run this assessment across three analytical lenses:
- Structure evaluates schema conformance, data types, and format consistency. Fields that shift between numeric, textual, or array representations become visible at this stage.
- Content analyzes value distributions, null rates, and anomalies. Invalid timestamps, placeholder entries, and out-of-range values can be quantified rather than inferred.
- Relationships test alignment across systems. Identifier drift and referential inconsistencies often explain reconciliation failures during reporting, indexing, or reindexing operations.
When teams skip this baseline work, issues tend to surface mid-migration as pipelines encounter unexpected data variation.
Determine the Optimal Target Schemas
Target schema design defines how data will be interpreted, joined, and governed after migration. Clean schemas in MySQL or accurate mappings in Elasticsearch are achievable once the structure reflects how the data is actually used across systems.
For that, you’ll need to establish a shared business language. Core entities such as customers, properties, transactions, or locations require definitions that remain consistent across systems and interfaces. This alignment reduces downstream reconciliation and prevents inconsistencies across system integrations.
This phase typically includes:
- Defining canonical entities and attributes used across systems
- Assigning ownership for high-impact fields and their definitions
- Setting expectations for optional, deprecated, or transitional attributes
Normalization follows once all key definitions are aligned. With standardized representations, equivalent data values behave consistently across ingestion, querying, and downstream processing.
Data normalization work usually covers:
- Aligning formats across data entities
- Correcting malformed or inconsistent values that affect joins and filters
- Standardizing date, time, and identifier formats
The next recommended step is creating controlled vocabularies. These further stabilize schema behavior. Status and state fields also support automation and segmentation as values follow a single, enforced representation.
This usually involves:
- Converging loosely defined or free-text fields into controlled enums
- Mapping legacy codes to canonical values
- Enforcing value constraints at ingestion time
Target schemas also introduce additional structure through derived fields. For example, you may want to split addresses into “street”, “unit”, “ZIP code” entries, or separate names into “first”, “middle”, and “last”. Parsing composite values and enriching records with calculated attributes improves how data supports operational and analytical use cases.
When schemas are defined this way, data analytics systems behave more predictably as volume grows and new sources are added. Custom Java mappers, Logstash conditionals, or data-cleaning services help enforce these through transformation layers.
Plan for the Common Data Ingestion Pitfalls
Large-scale data ingestion creates pressure by design. As volumes climb and sources converge on the same platform, pipelines start jostling for throughput, compute capacity, and the margin operators rely on to keep things stable.
Planning for these constraints early reduces instability during migration and steady-state operation:
Backpressure and Cluster Load
These issues arise due to the limited search cluster throughput. Search platforms such as Elasticsearch and OpenSearch distribute data indexing work across available nodes and shards, and the throughput levels depend on memory, disk I/O, and shard allocation.
When ingestion pipelines push large volumes of data at high speeds, the system becomes constrained: Queues build up, indexing slows, and query performance degrades. This delays data availability for customer-facing teams.
To keep ingestion aligned with cluster capacity, we recommend:
- Right-size shard counts based on data volume and query patterns
- Limit the number of concurrent ingestion workers per index
- Separate heavy write workloads from latency-sensitive search traffic
- Monitor indexing pressure, queue saturation, and node utilization in real time
- Re-configure injection schedules to avoid peak operating hours
Dirty Data
Dirty data are malformed or inconsistent records, which are often present in large datasets. For example, corrupted rows, invalid timestamps, inconsistent column counts, or placeholder values. When these records enter the ingestion pipeline without proper transformation, they can block the system or introduce silent data corruption.
Dirty data reduces the analytics’ accuracy — and data engineers have to allocate extra efforts towards diagnosing ingestion failures, instead of working on higher value-added tasks.
To minimize dirty data:
- Record validation and preprocessing before ingestion using custom ETL or Java processing layers
- Apply conditional transformations and coercion rules in Logstash pipelines
- Route malformed or rejected records to dead-letter queues for review
- Maintain structured logs to support targeted reprocessing and auditing
- Define clear acceptance criteria for data quality at ingestion time
With these best practices in place, you can improve data quality incrementally without blocking core operations.
Reindexing Without Downtime
Data reindexing is necessary when mappings change or normalization rules evolve. But in production systems, reindexing may interrupt data availability in operational workflows and BI tools.
To avoid downtime, we recommend the following approach: Rather than touching the live index, introduce a parallel structure and migrate data in the background. Then production traffic stays put while the new foundation takes shape.
Only once the data and structure are in place does the system switch over. Load is managed throughout, keeping the platform responsive while change happens out of view.
How to reindex data without downtime
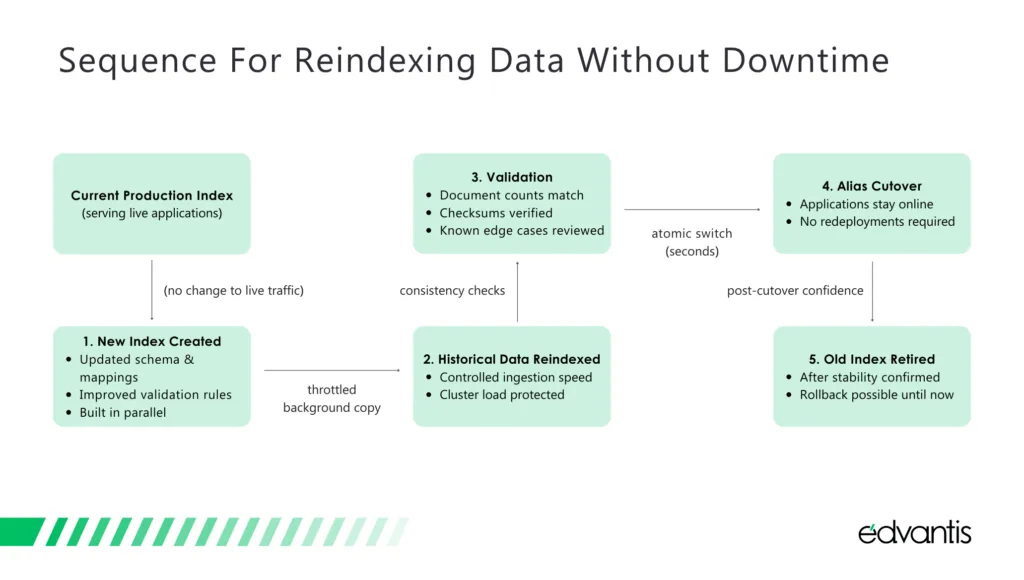
With this approach, applications remain available, dashboards continue to refresh, and operational teams avoid coordinated downtime windows or emergency rollbacks. Changes to data models become routine maintenance rather than high-risk events.
That said, some complications may happen. Scripted transformations can fail on unexpected data shapes. Nested fields may change ordering or structure. Concurrent ingestion can introduce conflicts while historical data is still being copied.
To reduce these risks, we recommend separating the reindex into two phases:
- A primary reindex of historical data
- A controlled backfill that captures changes occurring during the migration window
This approach limits data gaps and allows validation to occur incrementally. If issues surface, the system can continue operating on the original index while fixes are applied.
Reindexing strategies that use alias-based cutovers and staged backfills allow schema evolution to proceed without customer-visible impact. They also establish a repeatable pattern for future changes, reducing the operational cost of ongoing data model improvements.
Plan for the Future
Treating data migration as a single milestone misses the point. Centralized data continues to shift as the organization grows, operates, and adapts to external constraints, e.g., new customers sign up, transactions occur, products evolve, regulations shift, and so on.
Data platforms that weren’t designed for continuous change tend to accumulate follow-on work in the form of repeated remediation to-dos (or technical debt if you skip on those).
Future-proof data architectures treat migration as the foundation for ongoing data movement. Over time, initial backfills give way to scheduled and event-driven pipelines that keep systems aligned without repeated full reloads.
Here’s how the evolution to event-driven pipelines may look:
Daily Delta Ingestion
Rather than reloading entire datasets, pipelines move only records that have changed since the last run. This keeps operational views and reports current while limiting infrastructure usage and ingestion load.
Business impact:
- Faster access to new insights
- Lower cloud costs
- Reduced operational disruption.
Near-Real-Time MySQL Synchronization
Operational databases rarely stay static after migration. Customer actions, orders, payments, status changes, and system events continue to occur throughout the day.
Near-real-time synchronization streams these changes from MySQL into downstream platforms such as Elasticsearch or OpenSearch within seconds or minutes, rather than relying on batch reloads.
Support tools, customer activity views, operational dashboards, alerting systems, and risk monitoring benefit a lot from timely updates without requiring strict transactional consistency.
Business impact:
- Real-time access to key operational data
- Preventive, instead of reactive, responses
- Shorter decision cycles for growth initiatives
Logstash Nightly Loads
Not all data needs to move in real time to deliver business value. Many financial, compliance, and management reporting use cases benefit more from consistency and predictability than from immediacy.
Nightly ingestion schedules align these datasets without competing with peak operational workloads during business hours.
In this model, Logstash pipelines run during predefined off-peak windows to ingest and transform data from source systems into analytics or search platforms. The timing allows teams to apply heavier validation, enrichment, and reconciliation logic without affecting live customer transactions or operational systems.
Nightly loads are commonly used for general ledger snapshots, compliance extracts, operational summaries, and internal performance reporting. They also provide a controlled point for reconciling discrepancies across systems before data is exposed to broader audiences.
Business impact:
- Stable reporting cycles
- Fewer reconciliation issues
- Streamline audit preparation
Scheduler-Based Refresh Jobs
Some data flows don’t originate from a single system or follow a strict transactional pattern. But rather, they depend on the coordinated availability of multiple upstream sources, intermediate calculations, or external inputs. For example, the daily revenue from one retail location.
Scheduling provides a reliable way to orchestrate these refreshes when all prerequisites are met, rather than on a fixed ingestion clock. This way, you avoid partial updates and reduce the need for ad hoc scripts or manual checks. So you gain accurate reporting faster.
Business impact:
- Lower operational overhead
- Fewer human errors
- Improved data reliability
Regular Re-Ingestion After Normalization Improvements
Data normalization rarely reaches a final state in the first pass. As you develop a
better understanding of available data, definitions evolve, validation rules improve, and edge cases are handled more consistently. These improvements should be applied to historical records, as well as new data, for better consistency.
Regular re-ingestion allows organizations to reprocess historical data using updated normalization and transformation logic. Instead of maintaining parallel quality standards for old and new records, this approach brings the full dataset up to the same level of consistency. Over time, it prevents analytical drift, where trends and metrics become harder to interpret because historical data reflects outdated structures or rules.
Business impact:
- Stronger long-term trend analysis
- More reliable AI and forecasting models
- Consistent compliance across historical and current data.
Case: Building Real-Time Data Pipelines, Processing 180M+ Documents Monthly
In many cases, data rarely arrives in clean, predictable batches. One of our clients in the US real estate sector operates across thousands of jurisdictions, ingesting property and ownership data from dozens of providers. Each source follows its own schedule, format, and interpretation of “complete” or “correct.”
Every month, their system needs to ingest, reconcile, enrich, and recalculate over 180 million documents — and do so, without interrupting live search, analytics, or customer-facing applications.
The Data Landscape
The client’s data landscape reflected years of organic growth:
- Daily feeds with small volumes but complex business logic
- Monthly CSV drops measuring 10–15 GB across multiple files
- Semi-annual and annual full refreshes from counties and providers
- One-off datasets delivered with minimal documentation
Each dataset had to be resolved into a single, coherent view of properties, owners, and transactions. Simple appends weren’t viable as every new record required large-scale matching, validation, and rule-based merging against tens of millions of existing documents.
Monthly updates were the most demanding part of the pipeline. They were not the largest by volume, but they carried the most ambiguity.
For each record, the system had to determine:
- Whether the property already existed in the database
- Whether the ownership information was still valid
- Which fields should overwrite existing values
- Which changes should be ignored or retained historically
Small differences in spelling, formatting, or identifiers could change outcomes. A native pipeline would either duplicate records or overwrite valid data — and that’s what we wanted to avoid.
Designing the pipeline
Edvantis’ system integration team decided to go with a hybrid architecture.
We implemented Logstash to handle the initial streaming and preprocessing of CSV files. Its role was to normalize formats, enforce basic validation, and route records based on structural signals.
The core decision-making logic lived in custom Java processors. This layer performed record matching, cross-index lookups, conflict resolution, enrichment, and conditional updates. Records were written either to the primary index or to a historical index, depending on their lifecycle state.
Daily feeds introduced additional complexity. These updates required deduplication, partial merges, and real-time enrichment from multiple indices. Logstash alone couldn’t reliably support that logic, so we added custom ETL components to handle ingestion, business rule application, and writing of fully validated documents into the system.
Monthly recalculation at scale
Data ingestion, however, was only part of the problem. Each month, the client needed to recalculate derived metrics across the entire dataset:
- Probability of sale
- Pricing indicators
- Lead and contact likelihood
These calculations relied on pre-trained machine learning models hosted in Amazon SageMaker, combined with precomputed attributes stored in Elasticsearch. Recomputing everything at once would have overwhelmed the cluster and degraded search performance. Instead, the workload was deliberately fragmented.
So we went with Quartz scheduling and ran recalculation jobs city by city, and in some cases, ZIP code by ZIP code. This constrained memory usage, isolated failures, and allowed validation at each step.
The process followed a repeatable pattern:
- Extract a bounded dataset from the production index
- Enrich records with supplementary data from secondary indices
- Run in-memory calculations using controlled multithreading
- Write results to a historical buffer index
- Promote validated data into the primary index through controlled migration
Heavy computation stayed away from live traffic. Rollback remained possible at every stage. So there was no downtime or risks to data integrity.
The outcome
By structuring ingestion and recalculation around isolation and controlled concurrency, the platform processes 180M+ documents every month without disrupting live usage.
Search performance remains stable. Derived metrics stay current. New data sources can be onboarded without redesigning the pipeline.
This architecture established a foundation for continuous data evolution, where scale, change, and reliability coexist without constant firefighting.
Conclusion
Effectively, data migration is a discipline of judgment — how data is interpreted, transferred, verified, and kept reliable as systems and requirements keep shifting. From our experience, success tends to rest on two principles:
- Design for production friction. Expect uneven source data, finite ingestion capacity, and schemas that won’t sit still. Build with those constraints in mind rather than treating them as edge cases.
- Keep heavy lifting off the user path. Push transformations, validations, and recalculations into dedicated processing layers, well away from live queries and interactions.
Handled this way, migrations generate fewer downstream fixes, analytics become easier to trust, and the platform gains room to absorb automation, AI, and new integrations without constant architectural rewrites.
If you’re evaluating a migration or replatforming initiative, Edvantis would be delighted to advise you. We work with teams to design architectures, pipelines, and governance models that hold up under real operational load. Contact us for a personalized consultation.










