Beyond ETL: Building Streaming Data Pipelines for Real-Time Insights

Data management now defines how far operational efficiency can scale. Faster access to fresh insights directly influences profit margins. But the difficulty comes from the data layer itself. Real-time visibility often requires reworking how data is structured, queried, and moved.
Ineffective data pipelines, in particular, introduce an operational strain. A 2026 survey found that an average Fortune 500 company now has about 328 data pipelines and as many as 35-60 full-time engineers maintaining them, with an average cost of $2.2 million per year.
What’s more, these legacy batch-based data pipelines break 30-47% more often than more modern versions, resulting in 60 hours of downtime per month. When every hour of disruption carries a high cost, reliability becomes a business concern rather than a technical one.
Batch-based pipelines were designed for periodic processing under predictable loads, which limits their ability to support continuous data flows or latency-sensitive use cases, like embedded AI models in the manufacturing sector or real-time commercial intelligence engines in pharma.
In this post, we examine what goes into building streaming data pipelines — such that support real-time data delivery and transformation for modern analytics systems.
Table of Contents
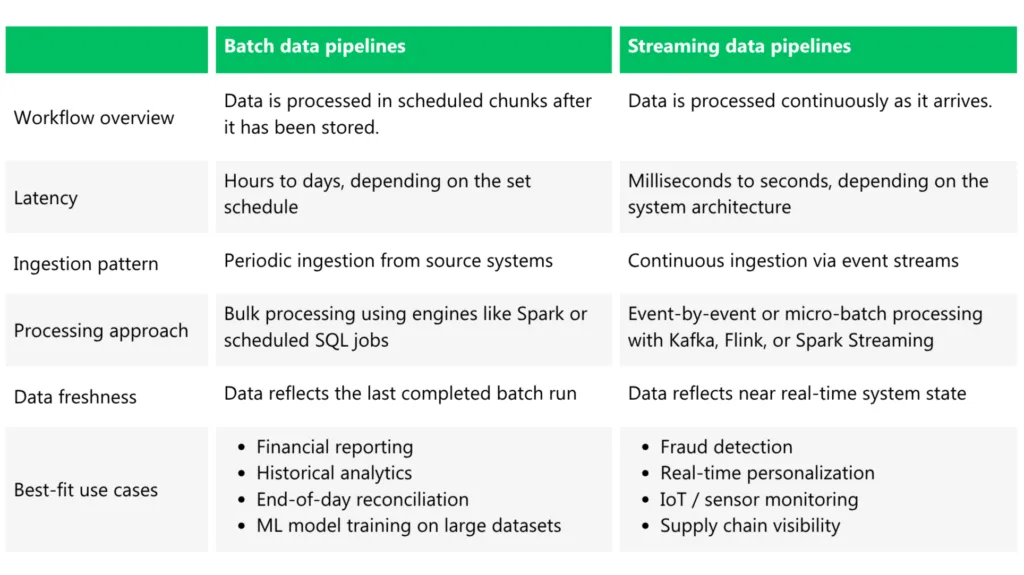
Batch vs Streaming Data Pipelines: What Are the Differences?
The main difference between batch and streaming data pipelines comes down to when data is processed and how quickly it can be operationalized (i.e., analyzed with BI tools).
Batch pipelines process data in chunks at pre-scheduled intervals (e.g., hourly, daily, or sometimes weekly) and then make a complete dataset available for downstream use after the processing is complete. For example, all local POS data gets synced to a cloud warehouse at the end of each workday and becomes available within a connected BI dashboard in 48 hours on average.
Streaming pipelines process data continuously, as events happen. Instead of waiting for a full dataset, the system pushes data through processing layers in near real time (i.e., in seconds or milliseconds), and makes it available to downstream apps like analytical dashboards, APIs, or alerting engines.
For example, data pipelines at TripleLift, an AdTech platform, can handle up to 30 billion events per day, 25 aggregation jobs with normalized aggregation of 75 dimensions and 55 metrics, and 15 jobs that ingest aggregate data into BI tools.
Effectively, streaming data pipeline architecture changes how systems behave operationally.
You move from processing “data at rest” to “data in motion”, where pipelines must handle ordering, duplicates, and failure recovery in real time.
Here’s a side-by-side comparison of the main differences between batch and streaming data pipelines:
Why Upgrade Your Pipelines to Support Real-Time Data Streaming
Re-engineering data architectures often stalls when leaders weigh the disruption risk against a hefty implementation bill.
However, replacing batch-based pipelines with real-time streaming versions for select use cases comes with proven ROI. Respondents to a Confluent survey reported benefits like better CX, improved risk management capabilities, more effective IT management, and transition to more data-driven operations, among others.
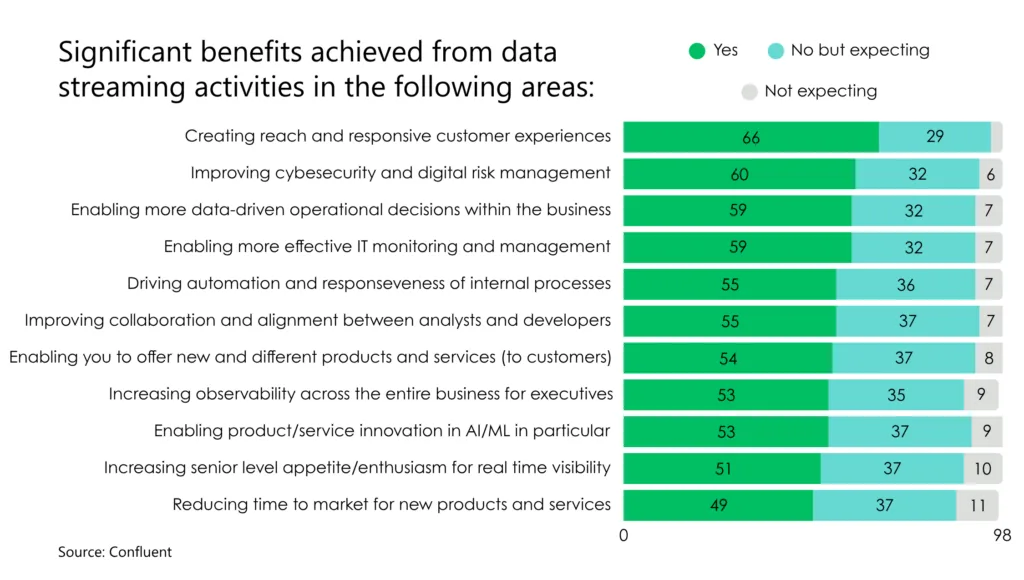
Source: Confluent
At Uber, the decision to switch to real-time streaming data pipelines was motivated by “data freshness and cost efficiency”, according to the team. Teams inside the organization were consistently asking for fresher data to power new model development and product experiments. Batch processing created delays. Replatforming to Flink reduced data latency to minutes.
In terms of cost, streaming pipelines eliminate batch scheduling overheads, enabling resources to scale with traffic more smoothly and efficiently. A recent benchmark report found that automated data integration alone saves about $300 per pipeline, which translates to six figures at enterprise scale.
For SEMDATEX GmbH, an Edvantis client, the decision to adopt streaming pipelines was driven by market competitiveness. The company was seeking to launch a new remote patient monitoring platform with real-time data ingestion from medical devices. Our team has created a streaming data pipeline architecture that enables continuous data collection and analysis while maintaining strict controls over data privacy and system security as required by German healthcare regulations.
Today, 86% of leaders are prioritizing investments in data streaming because continuously available data supports sharper decision-making, faster market response, and ultimately, more reliable revenue growth.
Best Practices for Building Streaming Data Pipelines
Streaming changes how your data systems behave (and what benefits they generate for your business). But it also raises the bar for how they need to be designed.
The following practices focus on what actually makes pipelines reliable in production, not just functional on paper.
Decide on the Optimal Streaming Architecture
Streaming data pipeline architectures take shape around constraints. Latency, state, and operational ownership determine which patterns could hold up under load and which ones create friction later.
Our data engineering team suggests starting with the latency requirements. Some pipelines need to muster sub-second responses, e.g., for fraud checks or patient monitoring. For example, Stripe streaming data pipelines for merchants have a query latency of < 70ms and 99.99% availability
Streaming data pipeline architecture at Stripe
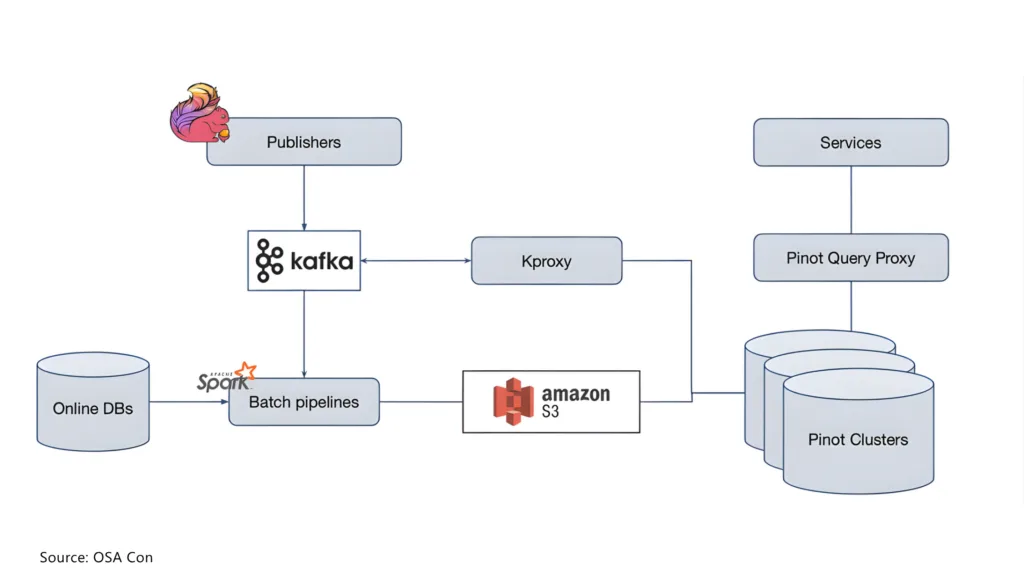
Source: OSA Con
But not all your data pipelines require sub-second updates. Other use cases can tolerate data ingestion every few minutes, which opens up simpler and cheaper design options. For example, you can opt for micro-batching using Spark Structured Streaming. It’s easier to plug into existing stacks and far less demanding to run than full streaming setups built on Apache Kafka with Apache Flink or Kafka Streams. Micro-batching also reduces the need for complex state management and continuous computation, lowering both infrastructure costs and operational overhead.
The next important decision is processing engine selection. Stateless filtering or routing can be handled with lightweight consumers or Lambda-style services. Stateful joins, aggregations, and windowing usually require engines like Apache Flink, Kafka Streams, or Spark Structured Streaming because they manage checkpoints, state stores, and recovery more reliably.
Lastly, consider managed services when operational overhead matters more than deep control over the architecture. AWS Kinesis, MSK, Glue Streaming, Lambda, and Azure Stream Analytics can reduce infrastructure management burden. This works well for teams that need faster delivery and can accept platform constraints around tuning, debugging, or portability.
Sample AWS streaming data pipeline
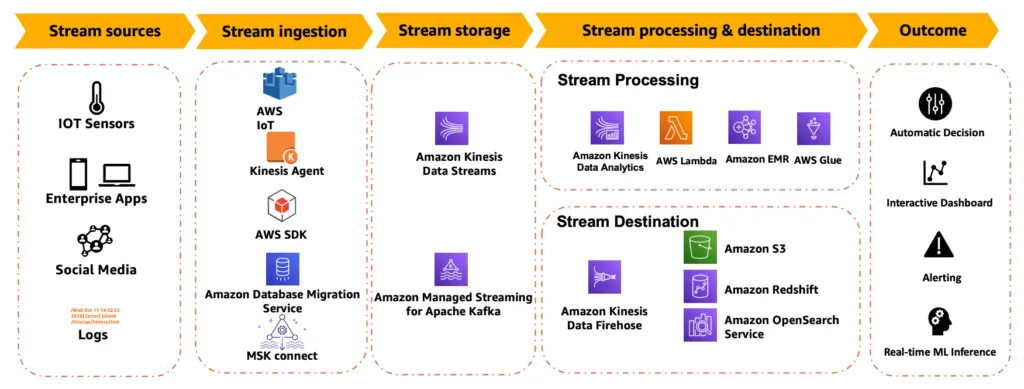
Source: AWS
On the other end of the spectrum, self-managed stacks lean into control. Setups built on Apache Kafka, Apache Flink, or Kubernetes tend to appeal when flexibility is the priority. Apache Airflow, an orchestration tool, also comes in handy for sequencing surrounding batch workflows and operational tasks.
What’s interesting is where that flexibility shows up: scaling decisions, data retention policies, partitioning logic, and even how workloads move across clouds. None of it comes for free. But if you need that level of control, these architectures can handle it.
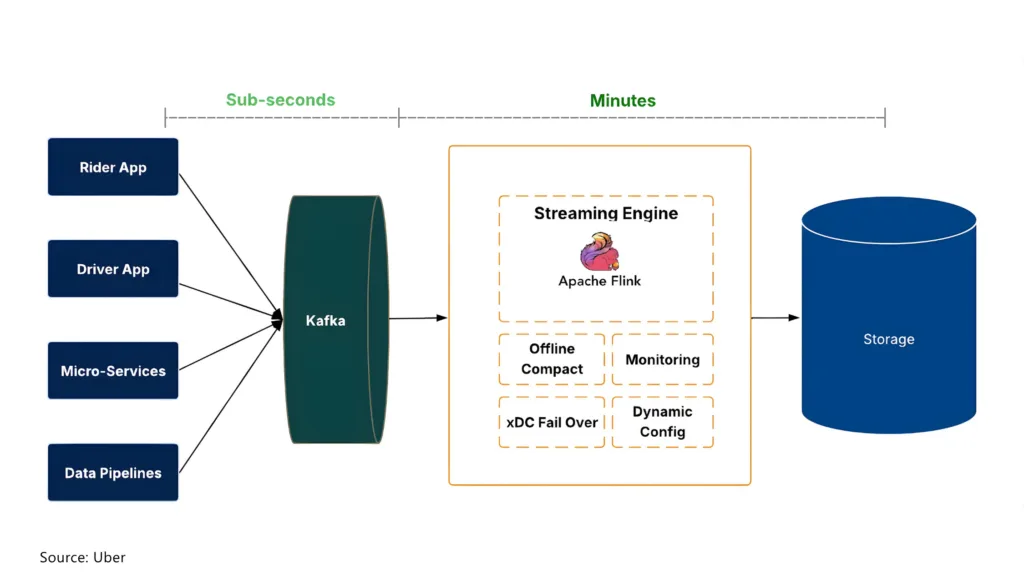
An open architecture can also be a good option if you’re dealing with high volumes of data and want to optimize costs. Uber, for example, went with Apache Kafka as the first layer to effectively manage ingestion at scale.
Sample streaming data pipeline architecture at Uber
Separate Ingestion, Processing, and Serving Layers
A typical streaming data pipeline has three core layers:
- Ingestion, where raw events are captured and persisted
- Processing, where data is transformed and enriched
- Serving, where results are delivered to applications and users
Creating a clear separation between each of them makes the ongoing pipeline management a far less taxing piece of work.
Start by separating ingestion from processing. Platforms such as Kafka, Amazon Kinesis, and Google Pub/Sub are popular options. Each retains events, supports replay, and decouples data producers from downstream consumers.
That decoupling matters. When source systems publish events into a shared stream instead of writing directly into downstream databases, teams can update processing logic or add new consumers without redesigning upstream applications.
That said, all data processing should remain centralized. Keeping filtering, enrichment, joins, and anomaly detection in a dedicated layer reduces duplicated business logic and makes changes easier to roll out across the pipeline.
The serving layer should follow access patterns, not infrastructure convenience. Low-latency application reads, operational monitoring, and analytical queries often require different storage systems, so separating this layer makes it easier to optimize each one independently.
This also improves resilience. If a serving database slows down, buffered ingestion and separate processing layers can continue operating, which limits the blast radius of downstream failures.
Bouygues Telecom used a similar approach to build its real-time network monitoring service:
- The ingestion layer aggregates over 4 billion events, generated by network equipment.
- The processing layer, based on Apache Flink, processes these streams in real time to detect anomalies, correlate events, and derive indicators of network quality and user experience.
- The serving layer feeds processed data to internal monitoring systems, enabling teams to understand what is happening across the network and respond to issues as they occur.
When each layer has its clear role, it can scale better, independently of others. Likewise, failures in one part of the system are less likely to cascade across the whole data flow.
Establish Effective Data Contracts and Governance
To prevent data silos, streaming data pipelines should have shared schemas and governance rules.
Data contracts define how data is structured and interpreted by downstream applications. This reduces ambiguity when multiple producers and consumers operate on the same streams. Typically, you should create separate data contracts for main event types, e.g., order_created or payment_authorized, in a schema format. The defined attributes and allowed values are then stored in a schema registry, from where both data producers and consumers can reference the same definition. Schema enforcement prevents malformed data from propagating downstream and simplifies integration.
As a rule of thumb, we also recommend codifying data quality standards at the pipeline level. You can describe “good data” in terms like completeness thresholds, acceptable null rates, or value ranges. Then set up automated data quality checks to detect quality issues before they creep into analytics apps.
Likewise, it helps define a clear breaking-change policy. Some changes will require coordinated updates across systems. For example, changing a field type or altering identifier fields can create issues in downstream applications.
A formal breaking-change policy clarifies when changes are considered breaking, how they should be communicated, and how migration windows are managed. Generally, you should maintain backwards compatibility for streaming systems to streamline management. As a fail-safe option, you can also introduce schema compatibility checks automatically in CI/CD pipelines to validate changes before deployment.
ING Bank relies heavily on its Schema Registry and automated breaking-change policy checks to maintain reliable data pipelines. The bank implemented strict schema validation at ingestion, restricting producers from publishing events that don’t match registered schemas. Invalid messages get rejected before entering the pipeline, preventing bad data from spreading downstream. Effectively, schemas became formal contracts between producers and consumers, defining structure, constraints, and expectations around the data.
Embed Security Into Streaming Pipelines
The last, but arguably the most critical step, is ensuring data security. Data flows across services, networks, and storage layers can create multiple entry points for unauthorized access or accidental data leakage.
To prevent that, authenticate and authorise every interaction. Producers, consumers, and all connected services should only use strong identity mechanisms (e.g., IAM, OAuth, mTLS) with role-based or attribute-based access controls.
Another good practice is encrypting data in transit and at rest. Consider TLS for all network communication and ensure storage systems enforce encryption by default, especially for sensitive data. As an extra measure, you can also create isolated environments for development, staging, and production data streams. Then apply network-level controls (e.g., VPCs, private endpoints) to limit lateral movement, and thus the odds of data leakage.
For more sensitive data streams, consider integrating security checks for pipeline changes. Every schema update, new consumer, or transformation should go through security checks and approvals where warranted.
Rabobank maintains a similar security setup for its streaming pipelines that process sensitive financial data. All services, interacting with Kafka, use strong, mutual SSL authentication, ensuring that only verified systems can produce or consume data. They also configured role-based access control for their 300+ DevOps teams, with each member having permissions only for their specific domains.
Generally, all teams operate in isolated, secured environments with defined boundaries, reducing the risk of accidental or unauthorized cross-access. All changes to data streams are tracked, which promotes further accountability.
Lastly, maintain access and data movement logs. Monitoring tools can show you who accessed what data, when, and how. This supports both incident response and regulatory compliance.
Conclusion
Batch pipelines did their job. They helped companies centralize data, standardize reporting, and bring some order to sprawling data infrastructure. But they were never designed for environments where decisions depend on what’s happening at this very second.
Streaming changes that equation. It enables teams to layer in real-time data into analytical models, personalization engines, corporate dashboards, and innovative products. Surely,
not every workload needs sub-second latency. But the ones that do often define customer experience, operational efficiency, and revenue performance.
If your current data pipelines are holding back real-time use cases, it’s time to rethink the architecture. At Edvantis, we help teams design and implement streaming data pipelines that balance performance, reliability, security, and operational cost. From selecting the right architecture to building production-grade systems, we work alongside your team to make real-time data actually usable.
Talk to our data engineering experts to determine where streaming can deliver the highest impact and how to get there without disrupting your existing systems.










