Why 2026 Should Be the End of Data Silos at Your Company

Most companies entered the new year with a renewed penchant for technology adoption, but also a substantial carry-over “baggage” — data silos.
In most cases, this baggage is inherited. One system added to move faster. One tool adopted to solve a local problem. One workaround that quietly became permanent. Yet over time, these decisions compounded and became fragmented data estates that slow decisions, inflate costs, and undermine trust in reporting.
The estimated cost of data silos per company sits at $3.1 trillion annually in terms of lost revenue and productivity. To prevent these losses from sprawling further, leaders should start treating data silos as a core business issue rather than just an IT clean-up task. Or they risk further falling behind in terms of AI adoption and operational intelligence.
In this post, we look at how data silos have reached the inflection point and how leaders should approach the systemic task of breaking it down.
Table of Contents
What are Data Silos?
Data silos are organizational and technical barriers that trap information within individual teams, systems, or business units. It means that data is ample, but it’s largely inaccessible, inconsistent, or disconnected from the rest of the organization. So different functions are optimizing for their own metrics, without seeing the full picture.
Take a retail company, where the ecommerce team sees strong demand for three product categories, based on online sales data. But the supply chain team plans inventory using lagging order fulfillment data. So stockouts are frequent, and shipping time is long.
Walmart fixed that problem by creating a unified data storage layer, which aggregates over 200 streams of internal and external data, including 40 petabytes of recent transactional data. This platform has become the pillar for its subsequent deployment of different AI apps, such as a predictive inventory management system.
The model suggests optimal seasonal inventory placement across stores and fulfillment centers, based on demand and availability signals. The unified data across physical and digital channels enables a consistent, omnichannel shopping experience during peak periods and beyond, according to Parvez Musani, Sr. Vice President of E2E Fulfillment.
Effectively, there are two ways to think about data silos:
- At an executive level, data silos represent a strategic risk. They limit visibility across the business, slow decision-making, and increase operating costs.
- At a technical level, silos magnify operating costs and hinder analytics adoption. When data is duplicated across systems, storage footprints grow unnecessarily large, and analytics, automation, and AI workloads become less reliable. Teams spend more time reconciling datasets and fixing pipelines than generating insight or value.
In 2026, both consequences are becoming more noticeable. Most businesses want to become data-driven organizations, but reporting often tells conflicting or outdated stories, causing substantial operational disruptions. AI adoption gets delayed as data scientists lack quality data to train algorithms. Security and compliance risks increase as information continues to proliferate across disconnected systems, with little to no oversight. Three-quarters of CISOs worry that silos and fragmented data obscure risks and create blind spots.
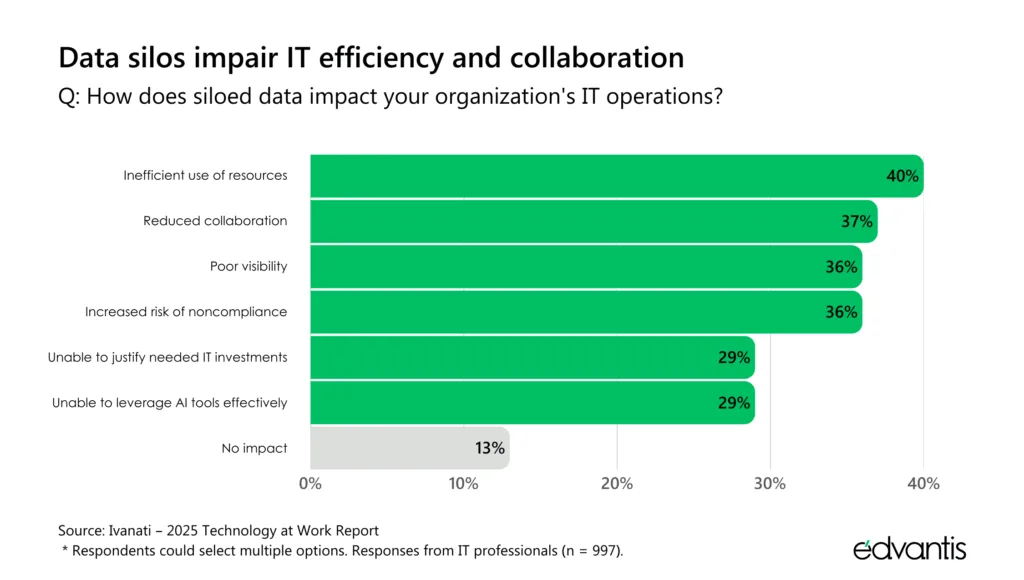
Source: Ivanati – 2025 Technology at Work Report.
The Causes of Data Silos
Data silos are rarely the result of a single lax decision. But rather, they are a by-product of sometimes haphazard adoption of point solutions across teams.
Over time, different business units end up with different technology stacks. With missing integrations, access to important information becomes constrained.
To that extent, the most common causes of data silos are:
- Fragmented application landscapes. Many organizations allow teams to choose their own stack, especially for functional needs. This is especially common in early-stage and high-growth companies, where speed matters more than proper governance. Yet, these early decisions often result in teams having overlapping systems that are poorly integrated and difficult to govern as a whole.
- Incompatible data models and storage systems. Multiple warehouses, lakes, and operational databases evolve in parallel without common schemas or interoperability principles. Subsequently, teams only run analysis against a bounded context, which reduces data reliability and increases the TCO of BI tools as more licenses are required.
- Point solutions optimized for local outcomes. In some companies, technology investments focus on departmental KPIs rather than end-to-end business processes. This reinforces isolation rather than alignment and causes further data fragmentation.
- Lack of a clear integration strategy. Systems are connected reactively through one-off ETL pipelines or manual workarounds, instead of through intentional, reusable integration patterns aren’t a sustainable solution.
- Organizational misalignment. According to Conway’s Law, IT system architecture often reflects internal communication structures. When your teams operate in silos, the data and systems they build tend to do the same.
This combination of technical debt and organizational design explains why data silos persist even in companies that invest heavily in digital transformation.
The Benefits of Breaking Down Data Silos
Addressing warehouse data silos is not a small feat. But the gains of doing so are substantial. By centralizing access to data, you increase its value and set the stage for stronger operational performance through:
- Ability to deploy AI and automation at scale. AI initiatives depend on accessible, comprehensive data. According to MuleSoft’s Connectivity Benchmark 2025, 95% organizations face data integration challenges that directly limit their ability to implement AI and automation. For 80%, data integration is the single biggest obstacle, which can be addressed as part of the data management transformation efforts.
- Stronger market foresight and predictive insights. Unified data enables more accurate forecasting, scenario modeling, and early signal detection. After modernizing its legacy data warehouse, our client in the real estate sector gained predictive lead scoring capabilities and predictive property valuation models, which improved portfolio performance and investment decisions across regions.
- Cross-channel and omnichannel customer experiences. When data is siloed, customer experiences end up feeling disjointed. Customer service asks the same questions. In-store assistants can’t help with an online order. And that’s a common issue in the service industry, too. More than half of banking executives admit to not having a unified view of their customers. Addressing data silos enables sales, marketing, and service teams to operate from the same customer context, across physical and digital channels.
- Stronger security and compliance posture. Lack of data visibility magnifies cyber risk exposure. Disconnected systems weaken visibility into sensitive data, access controls, and incident response. As cybercrime volumes grow and new data protection regulations take effect, the risks compound. With the average global data standing at $4.44 million, better data integration and governance are crucial for mitigating risk.
In short, addressing data silos strengthens decision-making, accelerates innovation, improves customer trust, and reduces risk across the business.
How to Eliminate Data Silos in 2026
Eliminating data silos is a leadership exercise before it’s a technical one. The goal isn’t just to move all data into one place, but to bring the right insights to the right people, so everyone has a trusted view of reality across the organization.
To achieve the above, Edvantis recommends focusing on four key actions:
- Run a data audit to identify priority candidates for de-siloing
- Create a new roadmap for the data estate
- Determine the optimal data integration strategy
- Create and implement a data governance strategy
Classify Which Data Should Be Desiloed First
Data de-siloing is not a mass migration exercise. You don’t have to move all data from a legacy database to a new cloud storage location. The goal is not consolidation for its own sake, but a better understanding of your data landscape.
Start with a structured data audit: Map where data currently resides, how it moves, who owns it, how it is used, and where friction appears. Our system integration services team usually analyzes:
- Storage systems types
- Exciting data lineage
- Interoperability gaps
- Access and security controls
Having some silos is justified. Some datasets may exist primarily due to regulatory or compliance requirements. For example, archival records, audit logs, or legally mandated copies. They need strict retention and deletion controls, but not broader access.
Other datasets may support a single team’s workflow and do not meaningfully inform decisions elsewhere. These should also remain purpose-built and well governed, but not deliberately moved to a shared data lake.
Instead, de-siloing should focus on operationalizing data that influences decisions across teams and business contexts. This usually includes the following categories:
- Real-time and operational data (e.g, customer interactions, supply chain signals, payment states, IoT telemetry). This is the data teams rely on to act in the moment. When it’s fragmented or delayed, response times stretch, errors compound, and service quality slips.
- Domain-owned data with cross-functional impact (e.g., marketing performance, product telemetry, sales metrics). These datasets are created inside one function but influence decisions across many. They should remain owned by the teams closest to the work, while staying accessible enough to support planning, prioritization, and executive decision-making.
- Collaborative and dynamic data (e.g., experiment results, machine-learning training data, product discovery insights). This data gains value through reuse and reinterpretation. Locking it away slows learning and limits its impact; making it discoverable accelerates iteration.
- Multi-format and unstructured data (e,g., text, images, video, logs). Non-tabular inputs rarely belong in a single system of record. The goal isn’t forced centralization, but findability, consistent metadata, and controlled access—so teams can use what they need without creating new blind spots.
As you work through your audit, keep one principle front and center: The North Star is to ensure that critical business decisions are informed by the same version of reality, regardless of function. So ask your teams this:
- Which decisions matter most to growth, risk, and resilience?
- Which data sources influence those decisions today?
- Where do handoffs, duplication, or blind spots distort outcomes?
The answers will likely guide you towards the priority data sources for migration and integration.
Establish a Shared Roadmap For Your Data Estate
Understanding your data estate is the easy part. The real test is whether the organization can agree on who owns the data, who can use it, and how it should travel across the business.
The most effective model for large organizations is a federated approach. Business domains can retain accountability for their data because they understand its context best. But shared standards, governance, and platforms are in place to ensure data consistency and accessibility. Autonomy without alignment recreates silos. Centralization without ownership slows execution. Federation balances both.
From a technical standpoint, this often means each domain operates its own lakehouse or warehouse while contributing governed datasets into a connected analytics layer. These domain data platforms then feed shared BI, data activation, and data analytics tools, so insights travel further than the teams that produced them.
For instance, e-commerce brand SKIMS recently consolidated over 60 data pipelines into a centralized warehouse built on Snowflake. The team then connected downstream tools such as Looker, dbt, and Census to feed more data into operational workflows.
They also combined internal data with Google Analytics clickstream data to surface metrics such as last-click attribution and customer behavior across channels. With a clearer picture of customer lifetime value and purchase patterns, teams could identify what made specific products successful and apply those insights to future launches.
A shared data infrastructure like this creates a common operating model for the entire company. Business units move faster because they have fast access to the latest insights. Leaders gain confidence because metrics are consistent. And the organization as a whole avoids drifting back into fragmented architectures as new tools and teams are added.
Create Your Integration Strategy
Once you have a general sense of how your data estate should look, it’s time to think about linking its elements — data storage locations to data-consuming applications.
Data integration is rarely a one-size-fits-all approach. Most companies rely on different data integration patterns, chosen based on system type, business needs, risk tolerance, and operating maturity.
API-led integration
Best for: Real-time interactions, customer-facing journeys, modular architectures
APIs support on-demand data exchanges between different apps by exposing well-defined interfaces that other systems can consume on demand. Instead of moving data in bulk or on a schedule, APIs allow applications to request only the data they need through a controlled contract.
Also, APIs can expose both raw data and business capabilities. For example, instead of providing direct access to a customer database, an API might expose operations such as get customer profile, update delivery preference, or retrieve order status, which enables greater workflow automation.
Advantages
- Enables real-time data access and responsiveness
- Supports product-centric and customer-facing use cases
- Encourages reuse and clear service boundaries
Trade-offs
- Requires strong discipline around versioning, ownership, and lifecycle management
- Poorly governed APIs can recreate silos behind clean interfaces
- Not the best option for legacy data migrations
Event-driven integration
Best for: Operational agility, decoupled systems, high-volume environments
Event-driven integration is built on a fundamentally different model from request-response APIs. Instead of systems asking for data, they publish events when something meaningful happens (e.g., new order, payment authorization, etc.), and other systems react to those. These updates are broadcast once and consumed by any number of downstream apps.
At a technical level, this integration relies on messaging infrastructure such as event brokers or streaming platforms. Events are immutable records that describe a change in state, not a request for information. This distinction is critical. It shifts integration from orchestration to reaction, and from tight coupling to asynchronous coordination.
Advantages
- High data analytics scalability
- Reduces dependencies between teams and systems
- Supports real-time operational intelligence
Tradeoffs
- Setting up end-to-end observability can be complex
- Requires event schemas, naming conventions, and versioning
- Built-in data error handling is required at consumer endpoints
Enterprise Service Bus (ESB)
Best for: Legacy-heavy environments with complex transformation needs
An ESB centralizes the integration logic of multiple subsystems with one control plane. Instead of building direct integrations, you connect applications through the bus layer, which handles routing, protocol mediation, transformation, and orchestration.
This pattern earned its keep in environments dominated by legacy systems. When applications lack APIs, emit inconsistent data formats, or rely on brittle protocols, an ESB provides a practical way to normalize complexity in one place. It’s less fashionable today, but still relevant when system modernization isn’t immediately feasible.
Advantages
- Simplifies connectivity across legacy applications
- Centralizes transformation and orchestration logic
- Reduces point-to-point integration sprawl
Tradeoffs
- Can become a bottleneck if overused
- Slows change when business needs evolve quickly
- Concentrates risk if not carefully governed
ETL / ELT pipelines
Best for: Structured data movement, repeatable data transformations
Extract Transform Load (ETL) and Extract Load Transform (ELT) pipelines move data in batches from operational and storage systems into analytical environments, according to a pre-set schedule (e.g., at the end of each workday).
Unlike APIs or events, which prioritize immediate access to fresh data, ETL/ELT pipelines focus on data accuracy and workload repeatability. So they’re often used for reporting, analytics, and regulatory workloads.
The difference between ETL and ELT is when data transformation happens. ETL pipelines transform data before loading it into the destination. ELT loads raw data first, then transforms it inside the analytics platform using scalable compute. Both approaches produce analysis-ready data, but they carry different costs, performance, and governance implications.
Advantages
- Strong auditability and reliability
- Cost-effective for stable, well-defined use cases
- Well understood and widely supported
Tradeoffs
- Limited flexibility for new or fast-changing data sources
- Not suited for real-time operational use cases
- Can create latency between events and insight
iPaaS (Integration Platform as a Service)
Best for: Rapid integration across SaaS-heavy environments
iPaaS platforms provide a managed layer for building and running integrations without owning the infrastructure. You get out-of-the-box access to prebuilt connectors, data transformations, and orchestration components delivered as a cloud service.
iPaaS is a good option in SaaS-heavy environments where speed and coverage matter more than fine-grained controls over each API. But it makes less sense for core transaction flows, real-time systems, or other use cases that demand deep observability and fine-grained controls.
Advantages
- Faster time to value
- Lower development and maintenance effort
- Broad connector ecosystems
Tradeoffs
- Introduces vendor dependency
- Can obscure underlying data quality and design issues
- Less control over performance and customization
Implement Data Governance
Some leaders think of data governance as a policy document, which you write once and then just keep somewhere in the corporate wiki. But that’s a recipe for further data silos.
Modern data governance is a codified, often automated, set of practices for ensuring data security, privacy, traceability, availability, and usability at scale. When approached both as an org principle and a set of technical controls, it supports data quality and greater analytics usage across the organization.
A practical data governance model usually focuses on a small number of non-negotiables:
- Automated quality checks at the pipeline level. Data quality requirements should be enforced as data moves, not post-factum. Automated validation, freshness checks, and schema enforcement, implemented at the pipeline level, prevent low-quality data from swamping data lakes and flooding analytical tools.
- Explicit data quality requirements. High-value datasets should be treated as products. Each one needs a clearly defined purpose and audience, documented quality and freshness standards, and clear criteria for when it should be deprecated or retired.
- Transparency by default. Governance works best when it is visible. This includes open data catalogs, clearly displayed ownership, and quality indicators that signal whether a dataset can be trusted. Easy discovery of approved data reduces shadow reporting and discourages teams from building parallel pipelines.
When teams can easily trace data lineage, understand broader surrounding context, and ensure the data is safe for usage, they spend less time wrangling with inputs and more on delivering business value.
Conclusion
To break down data silos, you don’t need to pursue a disruptive technical overhaul. On the contrary, start with easier ‘battles’ that will bring the fastest ROI — more scalable architecture for a data lake, used by several teams; additional integrations between fragmented apps, an automated data governance strategy for existing ETL/ELT pipelines.
If you need help with determining which data assets should be de-siloed first and how this should be best done, Edvantis’ engineering team would be delighted to assist you. You can learn more about our system integration service line or contact us directly for a personalized consultation.










