What are IT Operations Services? A Definition by Edvantis

More than ever, businesses are critically dependent on information technology (IT). High system availability, instant scalability, and unquestionable security are the critical quality characteristics organizations seek to cultivate.
To accomplish these objectives, many companies roll out new processes for IT systems design, management, and maintenance.
In other words: They focus more on the IT operations function.
Table of Contents
What are IT Operations?
Information technology operations (ITOps for short) refer to all the processes your company has in place to manage, monitor, and support IT systems. IT Operations Specialists keep your technical infrastructure running as it should — without disruptions.
Disruptions can come in the form of security incidents, network misconfigurations, or resource under-provisioning. Yet the outcome stays the same: Your company experiences costly downtime.
According to the Ponemon Institute, analyzed data center facilities had an average of 138 minutes of downtime per year. The number includes both isolated events across specific racks, as well as facility-wide shutdowns.
On-premises data center downtime, however, is just one source of disruption. Incidents also happen because of human errors, poor IT service management practices (Shadow IT), technical glitches, or subpar IT architecture design. Take it from Ticketmaster, whose IT systems failed to accommodate a surge in demand during a much-anticipated Taylor Swift concert sale. The company not only lost revenue in the form of unfulfilled sales requests but also took substantial reputational damage.
British Airways had a similar event in 2021, when most of its online systems went black for several hours, resulting in hundreds of flight cancellations and interruptions in airline operations. A post-mortem analysis found that the company made poor choices in backend architecture design. Their system lacked redundancies, so a failure in one central service catalyzed a string of other failures.
IT operations aim to ensure the availability, reliability, and security of its IT systems and corporate data — and prevent the above scenarios.
Functions Included in IT Operations Management
IT operations is an umbrella term for different workflows, processes, and expertise lines required to maintain an IT estate.
Typically, IT operations management (ITOM) includes any combination of the following functions:
- Network monitoring and management
- Application and infrastructure administration and monitoring
- IT facilities management
- Database maintenance
- Site reliability engineering (SRE)
- L2/L3 technical support
- Incident and security management
- Data backup and recovery
- Business continuity planning (BCDP)
- Disaster recovery (DR) planning
The above isn’t an exhaustive list, however. Each company has different operational requirements and commitments to customer service levels, which ITOM helps achieve.
Key IT Operations Roles and Responsibilities
ITIL defines IT operations management as a “functional team of people responsible for day-to-day maintenance and management of organization’s IT infrastructure to ensure delivery of the agreed level of IT services to the business.”
So, who are those people?
IT operations roles vary based on your industry and IT process maturity. Smaller organizations make do with a smaller ITOps team with roles like “System Administrator,” “Network Engineer,” and “Technical Support Specialist.” Their main responsibilities include IT system monitoring, data backup management, employee hardware, software provisioning, etc.
Organizations with bigger IT estates, and especially those pressed by customer SLAs, have multi-person ITOps teams with separate units in charge of:
- IT infrastructure management
- Application monitoring
- Network monitoring (e.g., NOC)
- Incident and security management (e.g., SOC)
- Site reliability engineering (SRE)
- Service desk management and tech support
Such teams can include any combination of ITOps roles like Application Analyst, System Architect, Operations and Network Engineer, Cybersecurity Analyst, and Compliance Analyst, among others.

How We View IT Operations at Edvantis
Since Edvantis is an outsourcing IT services provider, our view of IT operations services slightly differs from the ITIL definition.
We don’t see ITOps as specific teams or roles. Instead, we view IT operations management as a process that requires different competencies. Our goal is to provide clients with the IT expertise they need to run leaner, more stable operations.
Our engagement process with new clients starts with an operational benchmarking session, where we evaluate your current IT infrastructure, detail your objectives, and review current practices or key operational metrics. Based on this assessment, we suggest the scope of engagement and the ITOps talent required to meet the set operational goals.
IT operations management areas where we can help the most include site reliability engineering (SRE), technical support, and DevOps.
Site Reliability Engineering (SRE)
Site reliability engineering is the practice of applying software engineering principles to IT infrastructure management and operations. SRE promotes the automation of IT infrastructure tasks to ensure higher system performance, quality, and reliability. The SRE function also assists businesses in enhancing their IT resilience, which refers to their capacity to uphold high service levels even in the face of disruptions.
SRE is a set of tech principles and a cultural shift in team management. It attempts to resolve conflicting priorities that development and operation teams often face. In the words of Benjamin Treynor, VP of Engineering at Google and the mastermind behind SRE:
“At their core, the development teams want to launch new features and see them adopted by users. At their core, the ops teams want to make sure the service doesn’t break while they are holding the pager. Because most outages are caused by some kind of change—a new configuration, a new feature launch, or a new type of user traffic—the two teams’ goals are fundamentally in tension.”
Instead of relaying all system administration and maintenance tasks to the Ops teams, SRE encourages Software Developers to take greater ownership of system maintainability by automating repetitive tasks, reducing manual intervention, and improving incident response and resolution times.
Combining these practices increases system reliability — a newer IT metric that positively affects your company goals. When your core systems are reliable, you can confidently add new features and ship improvements without worrying about possible downtime. But when reliability is low, improvements in product functionality or software delivery pace don’t bring in tangible ROI. On the contrary: They may lead to unplanned disruptions.
Site Reliability Engineers ensure that your IT estate functions as it should under any conditions. Their everyday tasks include log analysis, performance optimization, patching, incident response, and mitigation. Most of these tasks are progressively automated. Doing so allows you to switch from a reactive to a proactive response to unplanned downtime or performance drop-offs and focus more on improving your customer SLAs.
SRE helps address the following issues:
- Frequent unplanned downtime and slow incident response rates
- Low visibility into the performance levels of various IT systems
- Overspending on IT maintenance tasks
- Operational silos between engineering and Ops teams
- Frequent system failures during releases
DevOps
While SRE focuses more on systems’ maintainability, DevOps reigns in the chaos within the software delivery process. DevOps methodology promotes faster, fail-proof software delivery through smart process integration and automation of error-prone tasks.
DevOps emerged to address the silos between software development and operational teams, which traditionally operate separately. This lack of alignment often results in issues during code deployments and release stages (e.g., due to incorrect code merges or mistakes in system configurations).
DevOps eliminates the risks of error by instituting a series of interactive, automated workflows with the Agile software development lifecycle.

The three main principles of DevOps are:
- Continuous integration (CI) is the practice of auto-integrating all code changes to a central repository frequently. Each integration triggers an automated build and test process to detect and resolve issues as early as possible.
- Continuous delivery (CD) is the practice of automating new software bulbs, tests, and deployment to production. The goal of CD is to ensure that recent changes are consistently and quickly delivered to users, while the risks of failure stay minimal.
- Continuous testing (CT) is the practice of integrating test automation into the software delivery pipeline to obtain fast feedback on code quality. CT ensures that every software change is thoroughly tested and meets quality standards before your team schedules it in the release queue.
More mature organizations also add “security” to this process loop. This practice is called DevSecOps. Instead of treating software security as an “after-thought,” DevSecOps encourages teams to incorporate security considerations during the planning stage and continuously implement them throughout the rest of the development cycle.
DevOps helps address the following issues:
- Frequent system failures and downtime during new releases
- Discovery of bugs and code vulnerabilities during the final stages
- A lengthy, manual, and downtime-prone release process
- Inconsistencies in code quality for different release candidates
- Low development and ops team efficiency due to siloed collaboration
Technical Support
Technical support (also known as IT support) function helps users resolve technical issues they’re facing with the product.
Larger organizations typically run two separate teams:
- An internal IT support team (a service desk) that deals with the employees’ IT problems.
- An external-facing tech support team that resolves the company’s customers’ queries, often based on the pre-agreed SLAs.
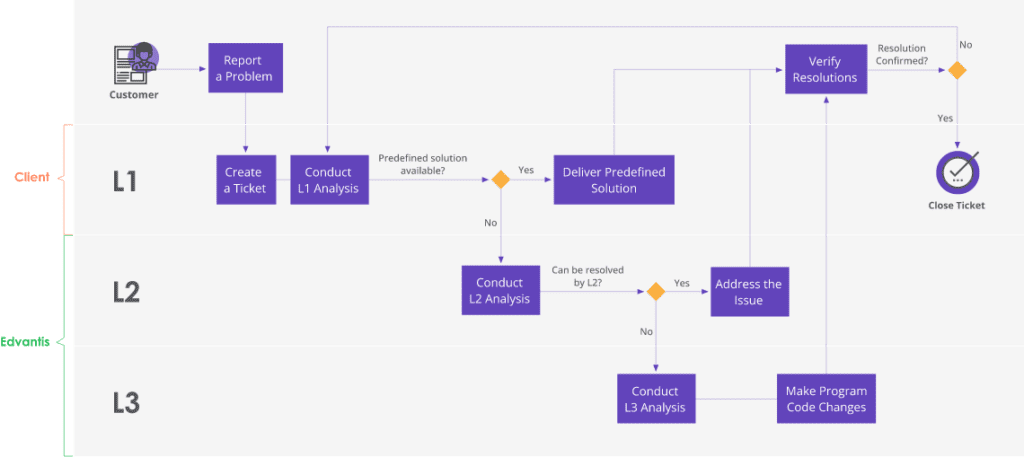
At the lowest level (L1), Technical Support Specialists work with incoming tickets and simple service requests (like password resets or new account provisioning access). At higher levels (L2/L3), competent Support Specialists and System Engineers investigate more complex cases (e.g., likely bugs, possible vulnerability reports, and other reported anomalies). Often, a company and its IT outsourcing partner share different tech support tiers.
A competent and readily available L2/L3 tech support task force is critical for ensuring stellar customer experience and high satisfaction levels with your products. Additionally, L2/L3 Engineers help identify critical system bugs and potential vulnerabilities, which often stand behind customer tickets. They provide development teams with feedback on system performance, security, and reliability issues discovered during the root cause analysis.
Technical support helps address the following issues:
- Slow issue resolution times, which affect customer satisfaction levels
- Low developers’ visibility into new feature requests or critical user-level issues
- Haphazard management and storage of sensitive customer data
- Inability to detect system vulnerabilities before they turn into a security incident
Conclusions
High-performing IT systems translate to seamless customer experience (CX) — a key factor that makes people select and stay with your business. At the same time, even a brief IT outage can send a ripple effect of disruption across your organization,
IT operations practices such as DevOps and SRE help your organization progressively curb the rates of planned downtime and rapidly recover from critical incidents. Yet both can be hard to institutionalize when your in-house teams lack the process and technology knowledge. That’s an area where Edvantis can help. Our IT Consultants can facilitate the implementation and perform the delivery of the outlined IT operations services. This way, your in-house teams can focus on growth-oriented tasks, while we take over IT infrastructure administration and optimization processes.
Contact Edvantis to receive a preliminary consultation on our IT operations services.











