Site Reliability Engineering (SRE) vs. DevOps: an Introductory Guide

DevOps and SRE are two Agile practices for developing and operating competitive digital products. Although both functions pursue the same ultimate goal — improve the quality and cadence of software delivery — they rely on different processes and practices.
The main DevOps vs. SRE difference is in the covered segments of the software development lifecycle (SDLC). DevOps prioritizes development (aka how new software is engineered and prepared for deployment), whereas SRE focuses more on deployment (aka how new software is deployed and performs in production).
To help you better understand the value of each function, we broke down the key DevOps and SRE concepts in this introductory guide.
Table of Contents
What is DevOps?
DevOps is a set of operational and cultural practices (plus tools) that automate and integrate the shared processes between software development and operations teams. The main goal of DevOps is to achieve higher velocity in software delivery: Enable teams to deploy new software features or products more frequently with lower failure rates.
In a traditional SDLC, software delivery is shared between two separate teams —Engineers and IT Operations Specialists. Software Engineers mostly focus on building new code faster, whereas IT operations teams aim to ensure that new releases won’t affect product performance rates.
Conflicts emerge when the two teams have somewhat antagonistic goals (release faster vs. release safely). Engineers push new code into production without considering possible integration issues or performance lags due to suboptimal infrastructure configurations. Ops teams delay releases because they’re worried about system stability due to possible bugs or infrastructure misconfigurations.
To avoid such tensions, DevOps promotes a “shift left” — aka focusing more on problem prevention rather than mitigation during the software development stage, not the release one.
Instead of performing quality assurance (QA) and software performance evaluation in production, DevOps encourages engineering teams to consider these metrics before the code is even written and continuously test against them during earlier stages of the SDLC.
In practice, this means verifying API design and configurations before the release, testing integrations between different microservices, using containerization, and so on.
Post-adoption, organizations report an overarchingly positive impact of DevOps:
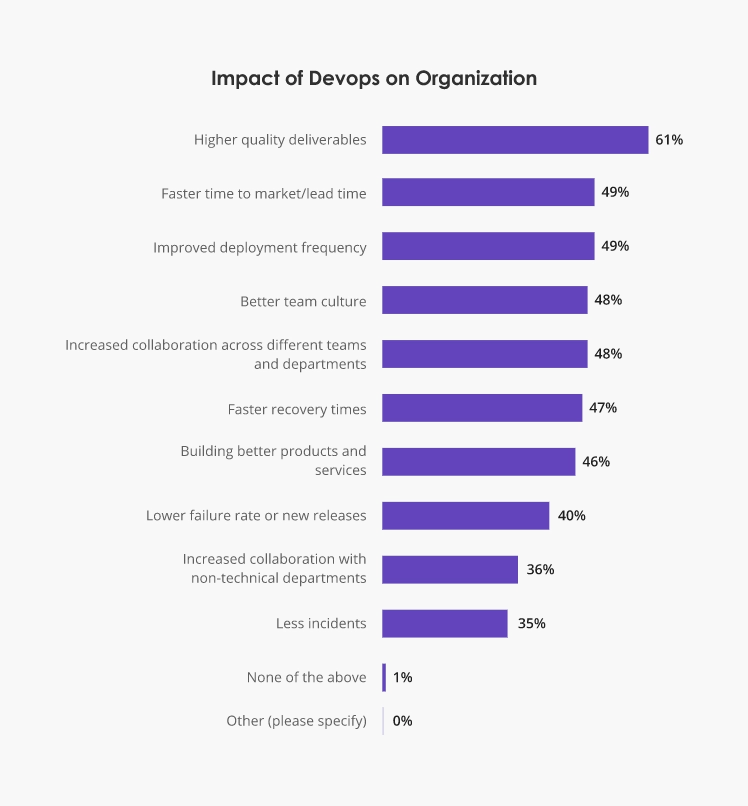
Source: Atlassian.
DevOps Lifecycle

The main stages of the DevOps lifecycle are:
- Plan: Determine the critical requirements for the new feature.
- Create: Develop new code that meets the above.
- Test: Automatically validate new code against quality and business requirements
- Release: Package new code for deployment
- Monitor: Observe the system behavior post-release
- Configure: Fine-tune the application, based on the systems’ response
Essentially, this lifecycle creates a continuous feedback loop where engineering teams consistently receive input on how new software performs in real-world settings, which can inform further product development or fine-tuning.
All new software comes out with the end goal: delivering a superior experience to end users with “always-on” services.
Key DevOps Principles
To achieve better collaboration between different teams, DevOps introduces workflows and automation solutions that fit the newly established product engineering lifecycle.
Essential DevOps principles and practices include:
- Automation with continuous integration (CI) and continuous delivery (CD) pipelines. CI/CD pipelines include semi- or full-automated “checklist” actions your teams must perform during software development. Automation helps reduce menial work and human errors and encourages teams to write clean code.
- Customer-centric action. Feedback from end-users informs product development. The DevOps lifecycle allows teams to rapidly collect, respond, and act upon user feedback.
- Continuous improvement. Through smart process optimization and automation, DevOps Engineers progressively minimize waste (time and resources lost to inefficiencies). Since it’s almost impossible to achieve software improvements without occasional failures, DevOps encourages rapid experimentation (failing fast) and subsequent feedback analysis.
What Problems Do DevOps Engineers Solve?
DevOps Engineers address the following operational challenges:
- Slow time-to-market for new software
- Low software development team velocity
- Complex, downtime-prone release process
- High rates of defects in the production
- Inability to deploy software updates frequently
- Growing disconnect between market demand and product capabilities
OK, What is SRE, Then?
Site Reliability Engineering (SRE) is a set of operational practices and engineering principles that automate the oversight and management of IT systems. SRE teams ensure that the corporate software systems can maintain high scalability, load tolerance, and security even under challenging conditions (think unplanned downtime, data center outages, etc.).
Similar to DevOps, SRE addresses another confrontation between engineering and operations people. Developers want to release a new feature fast and watch it take off at super-sonic speed. Operations people want to ensure that the new release won’t make the entire IT system tumble (because of unresolved technical debt, legacy software components, or subpar cloud infrastructure provisioning configurations).
SRE aims to resolve the debates on when and how to launch new features. SRE uses methods for green-lighting launches and smart IT infrastructure task automation for production system management, change management, incident response, and disaster recovery.
The above may sound like a regular sys admin job, but as Andrew Widdowson, one of the first SRE Specialists at Google, points out: SRE isn’t a candy-coated term for “operations.”
“SREs typically start out as rock star Software Engineers interested in becoming rock star Systems Engineers, or vice versa. And unlike most operations groups, SREs are a volunteer army — they are free to transfer to other compatible software engineering teams at any time if they don’t like the work or the environment.”
In other words, SRE Specialists are “free agents” who have great engineering and ops support skills and can shift to either side — development or support — depending on the current company goals. At Google, every SRE has to spend only 50% of their time on operational tasks (aka eliminating toil) and another 50% on writing code for new service features and designing new systems that would prevent technical debt accumulation.
Why invest in SRE?
SRE is a leaner IT operations practice for supporting rapidly growing technical estates. As corporate systems become more complex, spanning across multiple cloud and on-premises locations, system stability becomes hard to maintain.
Low visibility into your corporate estate can result in overlooked vulnerabilities (and subsequent security incidents), unplanned downtime (due to human oversight), or significant dips in up-time post-feature release (due to unheeded technical constraints).
SRE function helps businesses improve their IT resilience — the ability to maintain high service levels despite disruptions.
According to a Global SRE Pulse report, organizations primarily invest in SRE to reduce service failure rates and unplanned downtime; improve service delivery reliability; and trim the number and severity of incidents that affect end users.
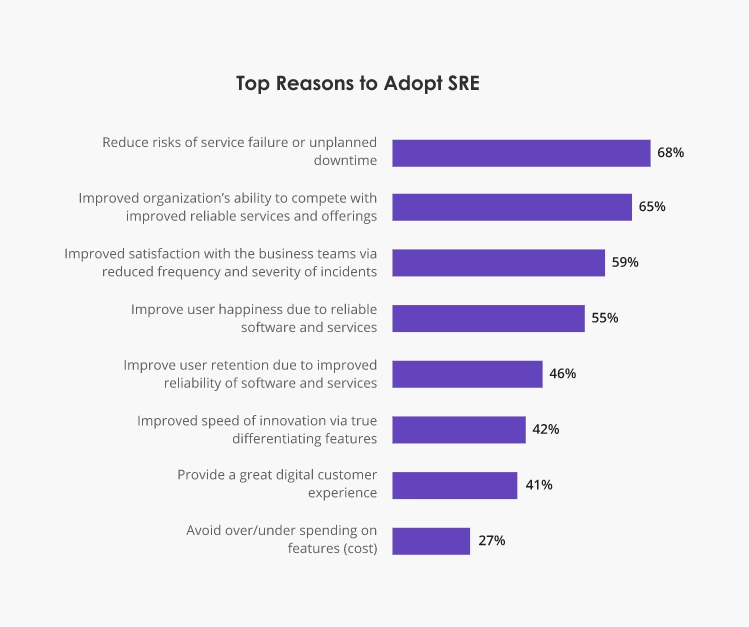
Source: DevOps Institute.
Key SRE Principles
SRE brings a software development mindset to operational problems. Instead of worrying about standard operating metrics (e.g., unplanned downtime percentage or SLA hit rate), SREs are encouraged to consider the big picture: End-user outcomes.
Sure, SRE teams are still responsible for standard operating tasks like system availability, latency, performance management, and capacity planning for new deployments. However, they rely on different tools and tenets to achieve these goals.
The main principles of SRE include:
- Risk assessments. All asset management decisions should consider risks. The higher the possible impacts of disruption are, the sooner you must address an issue. To avoid scenarios where “everything is a priority,” SRE introduces error budgets — a tolerable SLA threshold. Whenever a product deeps below it, pause all new launches until the error rates return to an acceptable level.
- Implementation of service level objectives (SLOs) — a target value or range for a service level, measured by a service level indicator (SLI). Both help understand what performance levels users want from the system and help determine what engineering work to prioritize.
- Eliminating toil. Similar to DevOps culture, SRE promotes the elimination of manual and menial operational tasks, which increase linearly with the systems’ growth.
- Comprehensive monitoring. You must monitor all company IT systems in production and validate them against selected performance metrics. This way, you’ll understand system behavior under real-world conditions.
- Focus on release engineering as it’s critical for ensuring the overarching system stability. Issues during the release stage (e.g., inconsistencies in configurations) can create a negative cascade of incidents, which SRE attempts to prevent.
- Simplicity-oriented engineering. Simple, modular system architectures and clean code are the cornerstones of long-term stability and agility.
For a deeper take, check Google’s SRE playbook that introduces and describes all the key SRE principles and practices.
What Problems Do Site Reliability Engineers Solve?
Site Reliability Engineers address the following operational challenges:
- High risks of unplanned downtime and high system latency
- Service level agreement (SLA) breaches and subsequent user dissatisfaction
- Low visibility into applications and system performance in production
- Growing technical debt and IT maintenance budget
- Low operational team efficiency and productivity
SRE vs. DevOps: Comparison Table
SRE and DevOps are more than new toolchains. Both assume changes in the processes and teams’ mindsets rather than technology adoption alone.
Although DevOps and SRE share overlapping areas of responsibility, they’re not mutually inclusive. DevOps’ focus rests more on software engineering and release management, whereas SRE practices aim to improve system performance in production and streamline a wider range of operational tasks.
One practice complements the other, with SRE often being the next evolutionary step after DevOps adoption.
To sum up, here’s a side-by-side comparison of DevOps vs. SRE.
| DevOps | SRE | |
|
Short role definition | System Engineers, solving development problems. | Software Engineers, solving operational problems. |
|
Owned SDLC stages |
Development and deployment stages | Release and management stages |
|
Key goal |
Improve development velocity, code quality, and deployment frequency | Improve IT infrastructure reliability, scalability, and security |
|
Main Use Case |
Application development | System management |
|
Usage of automation |
For software development, testing, and release management | For IT infrastructure and application monitoring. |
Edvantis offers DevOps and SRE services as part of our IT operations service model. Contact us if you would like to further learn more about DevOps and SRE implementation scenarios.











