Guide to Building an SRE Function: Principles and Best Practices

In 2003, Google faced a problem. The company grew aggressively but struggled to maintain high service availability due to sprawling infrastructure.
At that time, Ben Treynor Sloss, a VP of Engineering at Google, came up with the solution: Establish a site reliability engineering (SRE) function — a new unit in charge of IT operations tasks like infrastructure management and application monitoring.
Since then, companies from Amazon to Zoom have also established SRE teams. According to the Global SRE Pulse survey, 62% of organizations have established an SRE function, although the maturity levels vary. Over half have adopted SRE principles within specific teams, products, or services; 23% are piloting SRE, and 19% scaled SRE across the entire organization.
If you’ve been looking to establish an SRE function, this guide explains how to approach the adoption.
Why Do You Need an SRE Team?
You may be considering site reliability engineering because the way IT operations have been conducted has yet to yield satisfactory results. Cloud infrastructure costs are high, customer SLAs aren’t always met, and incidents are common when new code gets deployed. Sounds familiar?
Organizations establish SRE teams primarily to minimize service failures, reduce downtime, improve availability, and increase user satisfaction.
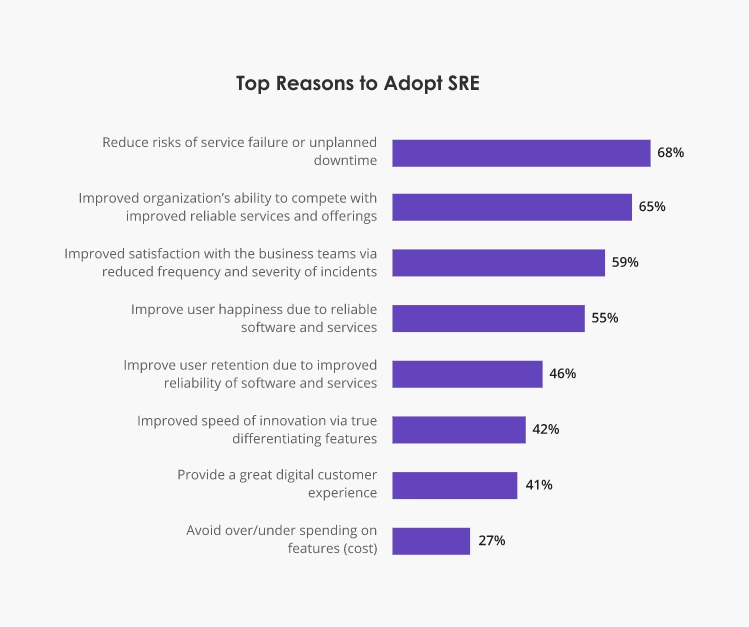
Source: DevOps Institute.
SRE teams focus on improving service stability and quality for end users, ensuring critical business applications run smoothly despite errors, outages, or peak traffic. To make that happen, SRE teams operate by a set of principles.
The main site reliability engineering principles:
- Operations are a software problem and thus should be solved as one.
- Manage by service level objectives (SLOs). Adopt appropriate target metrics for each service and work towards those.
- Minimize toil. Reduce or automate repetitive, manual tasks necessary to operate a production service.
- Automate this year’s job away. Spend roughly half the time eliminating toil via automation to free resources for more strategic tasks (e.g., new feature engineering).
- Move fast by reducing the cost of failure. To increase product developer velocity, aim to reduce the mean time to repair (MTTR) for common faults.
- Share ownership with Software Developers. Developers and Site Reliability Engineers have a shared toolkit and complete view of the available stack (frontend, backend, libraries, storage, etc).
- Use the same tooling regardless of function or job title. Standardize your toolkit to eliminate technology sprawl and integration issues.
Teams applying SRE principles report substantial benefits: Lower operating costs (12.5%), higher customer experience or satisfaction (12.5%), better system reliability, performance, or uptime (11.1%), better customer retention (6.5%), and avoidance of SLA penalties (6%).
How to Build an SRE Team: Best Practices
Similar to DevOps, SRE is a collection of cultural and operational best practices that encourage development and operation teams to collaborate instead of working against each other.
Common site reliability engineering best practices include a blameless culture, frequent retrospectives, active feedback, observability tools, documentation, knowledge sharing, and adoption of site reliability engineering metrics.
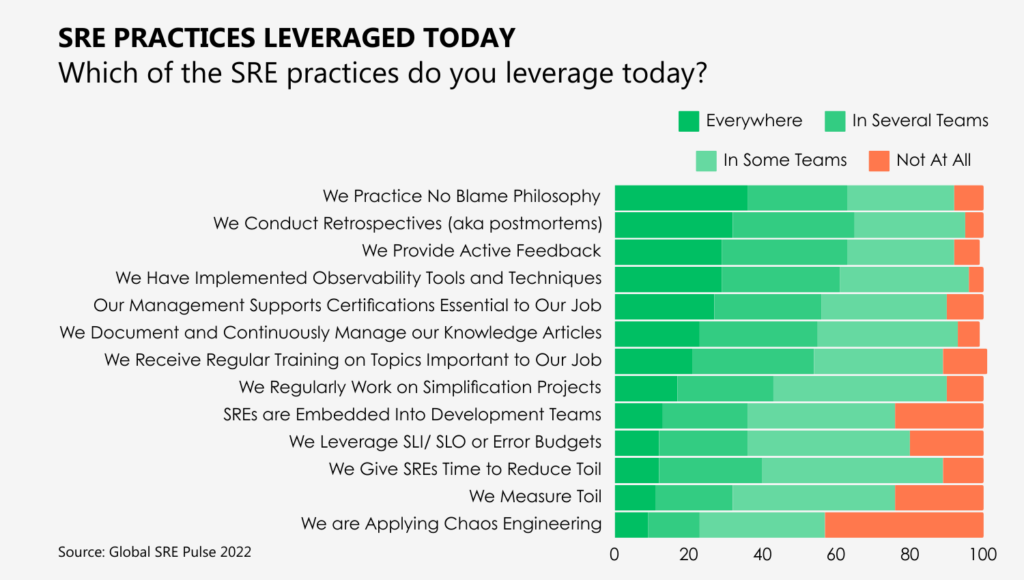
Source: DevOps Institute
Let’s see how these work together to establish a high-performing SRE team.
1. Decide on the Optimal SRETeam Structure
The first step to building an SRE function is organizational. You need to decide which teams or departments will run product operations. Work backward from your current organizational chart. Ask these questions:
- Who’s responsible for IT operation services? Is it a formal team or multiple individuals?
- Who’s responsible for keeping each product in production?
- Who’s in charge of fixing accidents during deployments?
- Who makes and prioritizes reliability-related decisions?
These help identify people already doing reliability work without a formal ‘Site Reliability Engineer’ title. Next, figure out how to define responsibilities and autonomy levels.
According to the “Establishing SRE Foundations” book, choose one of three SRE team structures:
You Build It, You Run It: There’s no separate operations team. All Developers shoulder SRE responsibilities on rotation or have dedicated Site Reliability Engineer(s) among them. The benefits of this SRE team structure are faster deployment, greater knowledge sync within the team, fast alert acknowledgment, and faster issue resolution. The downsides are a challenging setup of change management processes, high operating costs as multiple Developers may need to stay on-call, and a steep learning curve for the teams.
You Build It, SRE Run It: In this case, Developers only focus on delivering new code to production ASAP without thinking much about code operability. An SRE team has to figure out how to best run this in production with little guidance, leading to a growing chasm between the two units.
You Build It, You and SRE Run It: SRE responsibilities are shared between Developers and an SRE infrastructure team that handles various operations tasks. This is a solid middle ground that assumes proactive collaboration and a shared focus on metrics that matter to both teams.
Generally, organizations oscillate on this “who builds it, who runs it” spectrum, with most striving to create more incentives for development teams to implement reliability at the coding stage.
From an organizational standpoint, SRE teams can be either centralized (i.e., one unit that supports various products/services, platforms, and/or stack components, dedicated (i.e., in charge of specific product or service, platform-based (i.e., building capabilities on top of adopted cloud platform(s)), and stack-based (i.e., dedicated teams for each application or infrastructure stack).
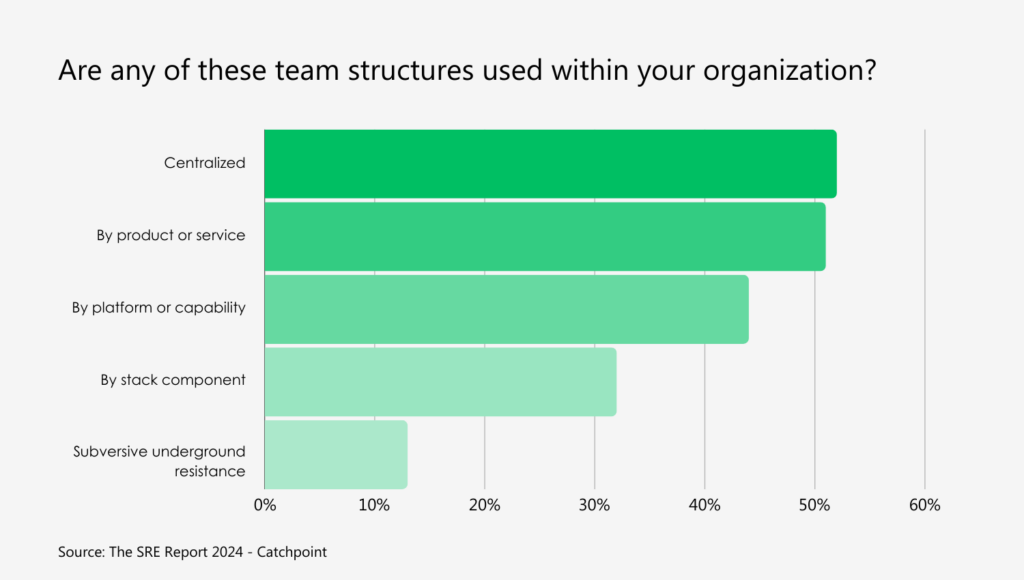
Source: The SRE Report 2024.
2. Establish the Key SRE Team Responsibilities
Site Reliability Specialists handle both operational and engineering tasks. They switch between managing infrastructure availability monitoring and incident management to developing new automation capabilities and toolkits to make their job easier.
Common SRE team responsibilities include:
- Development of new tools and capabilities to improve IT support processes. These may include solutions for observability, alerting, production code change management, and more.
- Application and infrastructure monitoring to ensure compliance with service-level objectives (SLOs).
- Automation of deployment pipelines (CI/CD); infrastructure provisioning and scaling to ensure seamless performance of new deployments.
- Proactive incident management — investigation and resolution of service outages and unplanned downtime; proactive minimization and prevention of incident recurrence.
- Capacity planning to ensure appropriate resource allocation for running services at present and safeguarding their performance in the future.
- Documentation of standardized operational workflows to ensure adherence to requirements and disseminate best practices.
- Post-mortems after incidents to analyze what went wrong, implement fixes, learn from the experience, and prevent future incidents.
In other words, Site Reliability Engineers perform multidisciplinary work, focusing on standard IT operations tasks and new product development (to support their work).
At Google, SRE teams typically include people with strong software development qualifications and rare technical skills for most Software Engineers (e.g., UNIX system internals and networking knowledge). Other companies promote Level 3 Technical Support Specialists to SRE positions or partner with managed IT operations services providers to staff the new unit.
3. Define Key Site Reliability Engineering Metrics
The goal of SRE is to improve application availability. You need metrics to ensure your unit works for the right cause.
The key site reliability engineering metrics are SLI, SLO, and error budget, which form the SRE concept pyramid—a framework for driving the SRE transformation. The higher your SRE team climbs the pyramid, the more sustainable its practice becomes.

Source: Infoq
Service-level indicator (SLI) is a quantifiable metric used to measure service performance and availability for customers. Common SLI metrics for SRE teams include:
- Request latency: the time required to return a response to a request.
- Error rate: number of errors encountered by a customer.
- System throughput: Number of requests per second delivered to different terminals.
- Availability: Period when a service is available.
- Yield: Percentage of successful service requests.
The performance of SLIs is typically measured as a percentage, with 0% being terrible and 100% being perfect. Combined, individual SLIs make up service level objectives (SLOs).
A service level objective (SLO) is a target your team must maintain for a service, like 95% application uptime. SLIs like availability and yield help capture these percentages so the SRE team knows where to focus when the benchmark dips below the targets.
Higher availability often means higher service operating costs. Teams first define the minimally acceptable reliability for each service and then determine the optimal SLO thresholds. With this minimal target, they can decide to invest in extra service reliability (higher costs and slower development) or keep it as-is (to develop new features faster).
New teams often set tight SLOs under pressure to improve SLAs. They struggle to maintain them due to limited budget or mission complexity, leading to breaches. Vladyslav Ukis, author of the aforementioned “Establishing SRE foundations” book and head of R&D at Siemens Healthineers, says that a good SLO:
- Reflects well the experience of a clear customer segment
- Can be defended by the team (i.e., feasible to deliver)
- Is accepted by all team members, including the Product Owner
Test different SLO hypotheses before documenting them in your service level agreements (SLAs) — a public commitment you make to customers regarding availability.
When SLOs are within the target range, customers are happy and don’t request compensation for an SLA breach. When SLOs dip, customers start complaining. An error budget represents the difference between the maximum service level and the SLO. For example, if your service availability has been 24 hours instead of 22 as per SLO, your team has an error budget of 2 hours per day.
This means your development team has some wiggle room. They can ‘spend’ the error budget on something other than optimizing SLIs. If your team doesn’t have any error budget, you’re likely struggling with high latency, low system throughput, or another low-scoring metric. Efforts must be diverted towards fixing that before new features.
4. Establish SRE Infrastructure
SRE promotes automation, meaning your team will need tools, scripts, and dashboards to do their work efficiently. Combined, these makeup SRE infrastructure—a tech stack several Sngineers will need to create and maintain.
Here’s what you can find in an SRE toolkit:
- Observability tools to aggregate and visualize telemetric data from different applications and infrastructure components.
- Monitoring tools with smart alerting, automated incident response, logging, visualization, and dashboards.
- Incident management tools to help with issue triage, establish escalation paths, investigate issues, and provide rapid remediation.
- Infrastructure automation tools to streamline environment provisioning and configurations, as well as automate deployment pipelines and orchestrate containers.
- Developer portal featuring service and resource catalogs and standardized tool kits all teams can use.
The primary purpose of SRE infrastructure is to provide a standardized, scalable set of tools an SRE team needs to perform its responsibilities and meet all the SLIs/SLOs. These help create consistency in workflows across teams to ensure fast alerting, efficient incident investigations, and fast median time-to-recovery. Usability should also be a priority since you want to ensure the adoption of all specialists.
5. Cultivate the Right Culture
Site reliability engineering is more than having the right team structures and appropriate toolkits. It’s a cultural shift, challenging you to rethink how you approach IT operations
at significant and challenging standard ways of software engineering.
Suppose your goals are to improve the release engineering process, eliminate toil, and maximize service level objectives. In that case, you should also coach your SRE teams to adopt cultural practices like blameless post-mortems, openness to measured risk, and proactive knowledge sharing.
Post-mortems (or retrospective meetings) are a common Agile project management practice that encourages candid conversations about the good and the bad. In SRE, post-mortems are usually conducted after a major incident (e.g., an SLO/SLA breach) to document the root cause(s), evaluate the response approach, and determine preventive actions to minimize the odds of issue recurrence.
The ‘blameless’ component means no team member directs fingers toward others or calls our inappropriate behaviors. By default, the conversation assumes everyone had the best intentions and did what they could to handle the problem. Adopting the second essential practice — embracing risk is hard without a blameless culture.
In SRE, embracing risk means teams allow a certain degree of unavailability to accelerate innovation and new feature development. This brings us back to setting the optimal SLOs. Most users won’t tell whether an app has a 99.99% uptime or a 99.999% uptime. But for Software Engineers, that 0.001% means either a stronger focus on optimizing availability or extra space to develop new product capabilities.
Likewise, stringent SLOs often translate to higher system operating costs. For example, you may need to maintain extra failover sites to ensure higher availability metrics (even if these are not warranted. Also, you have to switch more engineering resources to minimize the minuscule uptime risks instead of having them work on features that would have a higher impact on customer experience (and your business bottom lines).
In other words, SRE teams need to constantly assess the possible risks of focusing on one area over the other to maintain neutrality in service management. Error budgets and error budget-based decision-making are the two essential practices for that.
The final important responsibility of SRE teams is to share operations, software, and research knowledge with others to ensure everyone in your organization prioritizes service availability.
SRE teams produce, maintain, and circulate various types of documents, such as:
- Runbooks for handling different types of incidents or performing maintenance tasks.
- Incident reports summarise the issue’s root cause(s) and measures taken.
- Toil documentation specifying all system upkeep work to be automated and streamlined
Generally, SRE units help maintain a shared understanding of all systems, workflows, and tools within their zone of responsibilities and best practices for ensuring high system performance and availability.
Conclusions
Essentially, an SRE function establishes a centralized unit that oversees the day-to-day operations and contributes to the bigger picture — establishing reliable, secure, and scalable service operations. Such teams require multidisciplinary specialists with a solid understanding of software engineering best practices and substantial experience with infrastructure management.
With ongoing tech talent shortages, such people are challenging to find and complex to nurture internally unless your organization excels in IT operations. At Edvantis, we help our clients establish managed SRE units staffed with tenured specialists from our side and managed by your organization directly. Contact us to learn more about our approach to building high-performance SRE teams!










